
Publicly exposed resources are a leading cause of breaches in AWS. Security researchers will periodically do a deep dive into an AWS service, and try to divine the extent of public exposure. Today, I’ll take a turn, by looking at Amazon DocumentDB. Read on for details on the research, and for a deep dive on a public exposure impacting millions of customers of a publicly traded company :(.
🎉 Update! The company resolved the issue same-day following the publishing of this blog post. I also received a response on LinkedIn. They did not take ownership of the lack of VDP, I hope they’ll reconsider.
🎉🎉 2nd Update! Scott tracked down a documentation error that was leading to increased prevalence of exposed DocDB snapshots, and worked with AWS to fix it. Thanks Scott!
A history of deep dives into publicly exposed AWS resources
There are two basic pre-requisites to this sort of research:
- The resource must be publicly exposable
- There must be a way to enumerate instances of public exposure
A few prominent examples include:
| Date | Service | Researchers | Results | Link |
|---|---|---|---|---|
| August, 2019 | EBS | Bishop Fox (Ben Morris) | 50 Confirmed exposures, in a single region | More Keys than a Piano: Finding Secrets in Publicly Exposed EBS Volumes |
| January, 2021 | AMIs | Dolev Farhi | Analyzed 60,000 Public AMIs, found a variety of credentials and secrets | Hunting for Sensitive Data in Public Amazon Images (AMI) |
| May 2021 | SSM Command Documents | Check Point Research | Analyzed 3,000 documents, found 1 public s3 bucket with PII | The Need to Protect Public AWS SSM Documents |
| November, 2022 | RDS | Mitiga (Ariel Szarf / Doron Karmi / Lionel Saposnik) | Found PII, looked at 650 snapshots that were published by accounts that published a few more public snapshots (if at all), and without a keyword in their name that hints on the possibility it may be just a test | Oops, I Leaked It Again |
| April, 2024 | ECR Registry | Chandrapal Badshah | 111 valid AWS keys leaks, 14 belonging to root users | Securing the Cloud: Detecting and Reporting Sensitive Data in ECR Images |
| May, 2024 | AMIs | Eduard Agavriloae & Matei Anthony Josephs | over 200 valid AWS credentials | AWS CloudQuarry: Digging for Secrets in Public AMIs |
It turns out that DocumentDB snapshots also meet these criteria, and I wasn’t able to find prior evidence of research into public exposures.
Publicly Exposed DocumentDB Snapshots
Document DB (DocDB) is basically “AWS’s version of MongoDB.” It allows sharing snapshots publicly.
You can enumerate exposed snapshots with a basic CLI command. However, this only works per-region. The following janky python was used to get global coverage:
import boto3
import json
def get_regions():
client = boto3.client('ec2')
return [region['RegionName'] for region in client.describe_regions()['Regions']]
def fetch_list_of_regions_public_docdb(client):
raw_snapshots = client.describe_db_cluster_snapshots(
IncludePublic=True
)
raw_snapshot_array = raw_snapshots['DBClusterSnapshots']
return raw_snapshot_array
def fetch_list_of_all_public_snapshots():
snapshots = {}
regions = get_regions()
for region in regions:
client = boto3.client('docdb', region_name=region)
regional_snapshots, = fetch_list_of_regions_public_docdb(client)
snapshots[region] = regional_snapshots
return snapshots
snapshots = fetch_list_of_all_public_snapshots()
Across 28 enabled regions, there were a total of 634 exposed snapshots.
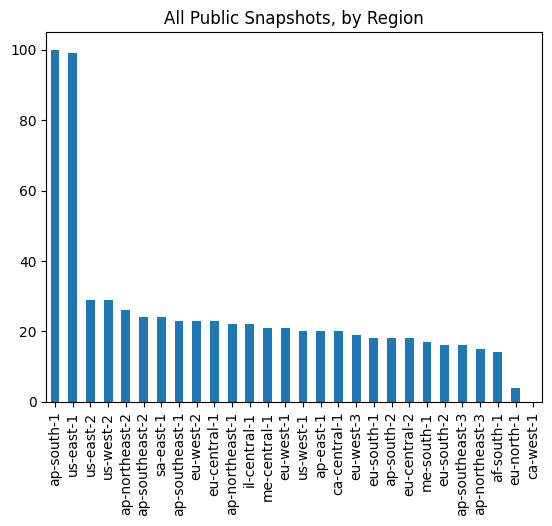
However, there is an idiosyncrasy. DocDB operates on top of RDS APIs.
This means these snapshots returned by the docdb API are not limited to just DocDB. We can tweak the code as follows:
def fetch_list_of_regions_public_docdb(client):
raw_snapshots = client.describe_db_cluster_snapshots(
IncludePublic=True
)
raw_snapshot_array = raw_snapshots['DBClusterSnapshots']
docdb_snapshots = []
for item in raw_snapshot_array:
if item['Engine'] == 'docdb':
docdb_snapshots.append(item)
return docdb_snapshots
def fetch_list_of_all_public_snapshots():
docdb_snapshots = {}
regions = get_regions()
for region in regions:
client = boto3.client('docdb', region_name=region)
regional_docdb_snapshots = fetch_list_of_regions_public_docdb(client)
docdb_snapshots[region] = regional_docdb_snapshots
return docdb_snapshots
docdb_snapshots = fetch_list_of_all_public_snapshots()
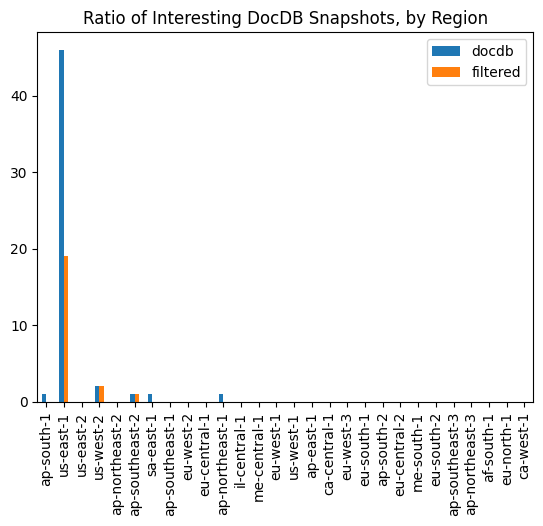
Of the 634, 52 were actually DocDB (based on the Engine field). These were only present in 6 regions.
We can further filter (fetch_list_of_regions_public_docdb) by name, after which roughly half do not seem particularly promising.
Code:
def fetch_list_of_regions_public_docdb(client):
raw_snapshots = client.describe_db_cluster_snapshots(
IncludePublic=True
)
raw_snapshot_array = raw_snapshots['DBClusterSnapshots']
docdb_snapshots = []
for item in raw_snapshot_array:
if item['Engine'] == 'docdb':
docdb_snapshots.append(item)
filtered_snapshots = []
for item in docdb_snapshots:
if (not item['DBClusterIdentifier'].startswith('rdsclustersnapshotnotpubliclyex')
and not item['DBClusterIdentifier'].startswith('canarybootstrap')
and not item['DBClusterIdentifier'].startswith('pb2keventcanary')
and not item['DBClusterIdentifier'].startswith('mydocumentdbcluster')
and not ('uat' in item['DBClusterIdentifier'] or 'test' in item['DBClusterIdentifier'] or 'qa' in item['DBClusterIdentifier'])
):
filtered_snapshots.append(item)
return raw_snapshot_array, docdb_snapshots, filtered_snapshots
Results:
| Pattern | Number of images |
|---|---|
Starts With mydocumentdbcluster |
27 |
Contains uat, test, or qa |
3 |
Here’s a view by creation date:
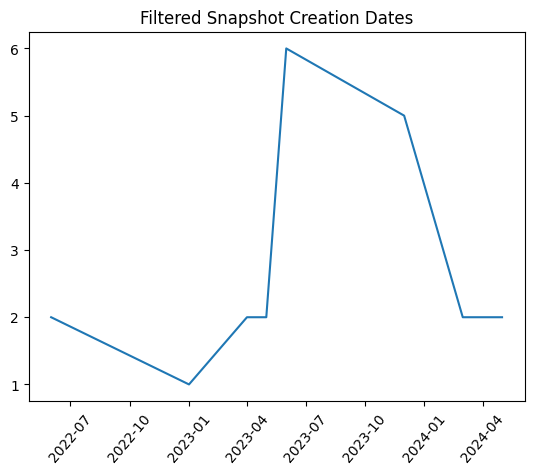
👎 We can further reduce our pool of “interesting” snapshots with a simple criteria - “is the size > 0.” Unfortunately, in a classic AWS inconsistency this data is only available via the console.
Of the remaining 22 snapshots - only one is not of size “0 Gb”.
How to dive deeper
The one remaining public snapshot is ~3.5TB, and located in us-east-1. It was created on 3/14/2024.
In order to analyze this singular snapshot:
- We restore it into our account as a cluster
- We reset the master password to one we know
- We create an instance in the cluster1
- Stand up an EC2 instance in the same VPC
- Connect from EC2 to the cluster, using the
MasterUsernameand the password we set in (2)
Diving Deeper
Once connected to the instance, the following mongo shell commands can be used for reconnaissance:
- List the databases:
show dbs->Cinemark 3.56 TiB - Select the database:
use Cinemark - List the collections (think, “tables” in a relational DB):
show collections... AppUser ... Discount Discount_bkp_18-10-22 Discount_bkp_20-10-21 ... Order ... Payment PaymentCardToken PaymentCardToken_BKP_01-07-22 PaymentCardToken_bkp_30-06 PaymentCardToken_copy PreUserRegistration ... Push PushMessage ... RecurrentPayment RecurrentPaymentHistory RecurrentPaymentUpdateAmount RecurrentPaymentUpdateAmountHistory ... SessionParameters ... temp_order temp_ticketId_reset temp_userOrders ... UserDevice ... users UserToken - You can grab a sample record from a collection with
db.users.findOne(), and get the size of the collection withdb.users.estimatedDocumentCount()
Overall, this public database appears to contain the data from Cinemark (NYSE: CNK), specifically Cinemark Brazil.
The users collection contains 8,418,642 records dating back to ~2010, each with a subset of: Name (first, last), email address, gender, CPF (Cadastro de Pessoas Físicas), member code, address, phone, date of birth, IP address, a “Password” field with a short hash, and more.
The Payment collection contains 10,752,176 records, with: card holder name, card BIN + last 4 + expiry, and more.
Coordinated disclosure (would have been nice…)
I was unsuccessful in disclosing this issue to Cinemark prior to publishing. They had no published security contact, security.txt, bug bounty, or vulnerability disclosure program (that I could identify).
Thu, May 16 - email to Security@ - bounced
Thu, May 16 - email to aws-security@amazon.com (for assistance notifying Cinemark or resolving the exposure) - response Mon, May 20 after back and forth: “Please note, the security concern that you have reported is specific to a customer application and / or how an AWS customer has chosen to use an AWS product or service. To be clear, the security concern you have reported cannot be resolved by AWS but must be addressed by the customer, who may not be aware of or be following our recommended security best practices.”
Fri, May 17 - attempt to contact apparent Security leadership via LinkedIn - no response
Mon, May 20 - email to Support@ - bounced
Mon, May 20 - twitter DM to @Cinemark - no response
Fri, May 24 - this blog initially published. A few hours later, the issue had been resolved and I got a reply via LinkedIn.
This is especially disappointing given that the subject is a multi-billion dollar publicly traded company.
While AWS is accurate in placing this issue on the customer side of the shared responsibility model, I’m still disappointed. Given the footgun, I’d love to see AWS show more Customer Obsession and Ownership in handling easily validated reports of customer exposure, at least via routing security disclosure of this sort. They’ve done so in the past, but the criteria isn’t clear.
Takeaways
- DocDB is weird! I was surprised to learn how it overlaps with RDS
- If a service allows public exposure and enumeration, customers will leak data
- There is a lot of juice left to squeeze in taking existing research and applying it to new services!
- Given that the one sensitive snapshot was only exposed a few days before I conducted this research, it’s likely ongoing monitoring would find short-term exposures (as was done in Mitiga’s previous research, for example)
-
In this case the cluster snapshot was Engine Version 3.6.0, so only Previous Generation (R4) instances were supported ↩