On Sequoia Capital’s Crucible Moments podcast, Paypal co-founder Max Levchin recounted the company’s early struggle to combat fraud. Their breakthrough came with the first large scale application of human interaction proofs, in the form of the now ubiquitous CAPTCHA.
This complemented a recent conversation a coworker started around Private Access Tokens as a potential replacement for exisitng human interaction proofs.
Together, these led me into a refresher on the history of CAPTCHAs and related solutions.
1996: Verification of a human in the loop
1996 Moni Naor wrote an (unpublished) manuscript entitled “Verification of a human in the loop, or Identification via the Turing Test” [download link].
It proposes ‘using a “Turing Test” to verify that a human is the one making a query to a service over the web.’ Example tests, some problematic, are drawn from the disciplines of Vision and Natural Language Processing:
- Gender recognition
- Facial expression understanding
- Find body parts: Given a picture of an animal, click its eye
- Deciding nudity
- Naive drawing understanding
- Handwriting understanding
- Speech recognition
- Filling in words
- Disambiguation: What does “it” refer to in the sentance “The dog killed the cat. It was taken to the morgue”
1997: Patenting Human Interaction Proofs
The following year, two teams concurrently patented similar “turing test” concepts:
- Eran Reshef, Gili Raanan and Eilon Solan filed a patent as part of work on a web application firewall.
- Mark D. Lillibridge, Martin Abadi, Krishna Bharat and Andrei Z. Broder also filed a patent, as part of their work at Alta Vista.
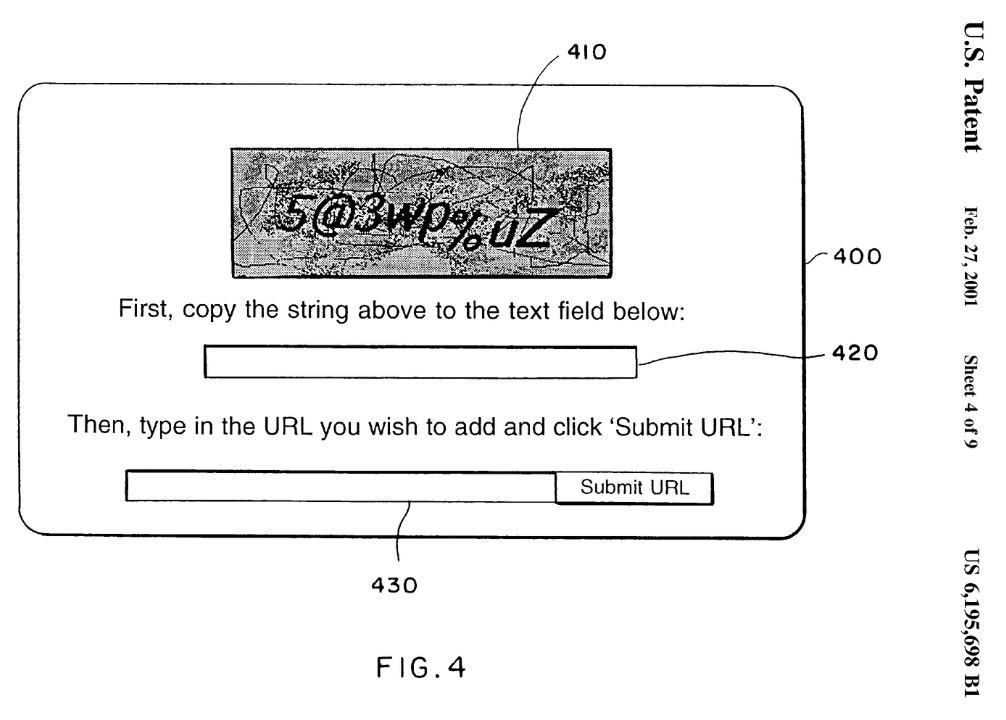
These “turing test” bot deterence solutions are predicated on a very basic concept: there are certain tasks that are easy for humans yet still hard for computers. The classic form relied on the known difficulty of OCR (“Optical Character Recognition”), by presenting distorted text for the user to identify.
The 2000s
Coining CAPTCHA

Carnegie Mellon University researchers Luis von Ahn, Manuel Blum, Nicholas Hopper and John Langford started The CAPTCHA Project in 2000. This coined CAPTCHA, standing for Completely Automated Public Turing Test To Tell Computers and Humans Apart.
Gausebeck-Levchin test
David Gausebeck and Max Levchin, while trying to combat fraud at Paypal, deployed one of the first practical CAPTCHAs in 2001. They named it the Gausebeck-Levchin test, which displayed distorted text.
Yahoo Gimpy
Yahoo worked with the CAPTCHA team to create and adopt Gimpy, which displayed distorted words from a 850 word dictionary. In 2002, a team from UC Berkley came up with the first automated attack against Gimpy. They showed an 83% success rate against an easy Gimpy, and a slower and less successful (30%) rate against harder Gimpy. This started a long pattern of researchers both deriving harder CAPTCHAs, and breaking them.
Improving CAPTCHA
In 2003, the original CMU team behind CAPTCHA published CAPTCHA: Using Hard AI Problems for Security. The paper genericizes a theoretical side benefit of using hard AI problems as the basis for CAPTCHA, such as was done with OCR. It proposes that doing so it will spur research and investment into solving those problems, advancing the field of AI.
Image CAPTCHAs
A 2005 paper introduces IMAGINATION, which moves beyond distorted text to CAPTCHAs based on distorted images.
Asirra
Microsoft came up with a CAPTCHA system in 2007 that relies on the ability to distinguish between cats and dogs. Asirra leveraged a partnership with Petfinder.com to source the images. Asirra closed permanently in 2014.
Spinning out ReCAPTCHA
The CMU CAPTCHA project came up with ReCAPTCHA in 2007. This was an extension of OCR CAPTCHAs, that additionally served to digitize text that OCR could not. It started with a focus on digitizing old editions of the New York Times.
Luis von Ahn led a spin out of ReCAPTCHA in 2007 to a dedicated company of the same name. Google acquired ReCAPTCHA in 2009, and went on to apply it to text from Google Books.
2010s: Evolving ReCAPTCHA
Google first expanded ReCAPTCHA in 2012, adding in images of street names and addresses from Google Maps.
In 2013, they released No CAPTCHA reCAPTCHA. This “v2” of ReCAPTCHA moved to performing behavior analysis for risk assessment, at times allowing a “single checkbox” verification for low risk users. This also brought along with it a more rapid iteration cycle for new challenges, starting with image labeling.

In 2017, this was further enhanced into an “invisible” reCAPTCHA that leveraged similar behavior analysis, but fully backgrounded and a chance of no challenge at all in low risk cases.
ReCAPTCHA v3 then lauched in 2018, which made the scores for various requests transparent to the site embedding the CAPTCHA, allowing for more granular control over when and how CAPTCHAs were served.
2010s: Privacy and CAPTCHA
The behavior analysis approach to human interaction proofs has raised privacy concerns. In order to perform this analysis, device profiling and cookie-based data collection are made even more prevelant. Coverage of privacy conerns have especially targetted Google’s ReCAPTCHA.
hCAPTCHA
hCAPTCHA launched in 2018, and positioned itself as a privacy focused ReCAPTCHA alternative. Initially, hCaptcha showed images from datasets companies are paying to label. This allowed websites that host hCaptcha to be compensated. Starting around 2022, labeling was spun off into Human Protocol.
Privacy Pass
Privacy Pass is one protocol that emerged around 2018 to try to provide a privacy-oriented CAPTCHA alternative. The basic premise allows for each challenge solution or proof of human interaction to grant many anonymous tokens that can be exchanged in the future in lieu of a new challenge. These “passes” are blindly signed and anonymously redeemed. To work cross-site, the protocol uses a browser extension.
Privacy pass never got substantial adoption - Cloudflare (who were the main industry proponent of the protocol) and hCAPTCHA are the only two providers who supported passes.
2020s to Now
Recent history has shown increasing pressure on the security of CAPTCHA challenges, and a continued focus on coming up with privacy preserving soltuons to human interaction proofs.
Cryptographic Attestation of Personhood
Cloudflare continues to be a vocal participant in this discourse. In 2021, they prototyped a “Cryptographic Attestation of Personhood” approach. This solution relies on a WebAuthn Attestation to “prove you are in control of a public key signed by a trusted manufacturer.”
Proof of Work Challenges
Another alternative to traditional CAPTCHAs that has been investigated are Proof-of-Work Challenges. Several implementations have emerged in the past few years, such as mCAPTCHA. However, PoW Challenges are not actually a human interaction proof, and so may not serve as a direct replacement.
Private Access Tokens
Cloudflare took another swing in 2022, partnering with Apple to expand on Privacy Pass with Private Access Tokens. Only Fastly and Cloudflare are Private Access Token Issuers, while Apple attests to the user’s identity.
Turnstile
Cloudflare’s late 2022 move in CAPTCHAs was the launch of “Turnstile.” This rolls up other technologies, including behavior analysis of telemetry and client behavior. It also builds in Private Access Tokens. It additionally, as was done with ReCAPTCHA, offers a platform for them to test additional challenge components. Up front they’ve suggested “proof-of-work, proof-of-space, probing for web APIs, and various other challenges for detecting browser-quirks and human behavior”.
The Current State of CAPTCHA
For almost thirty years, CATPCHA have been a fact of the web, a small necessary evil. To reduce the cost on service providers, accessibility and user experience has been sacrificed. Where has this left us?
Just a few years after their invention, creator Luis von Ahn realized:
he had unwittingly created a system that was frittering away, in ten-second increments, millions of hours of a most precious resource: human brain cycles
In 2022, Demystifying the Underground Ecosystem of Account Registration Bots looked at top sites and found the following break down of Human verification methods in use:

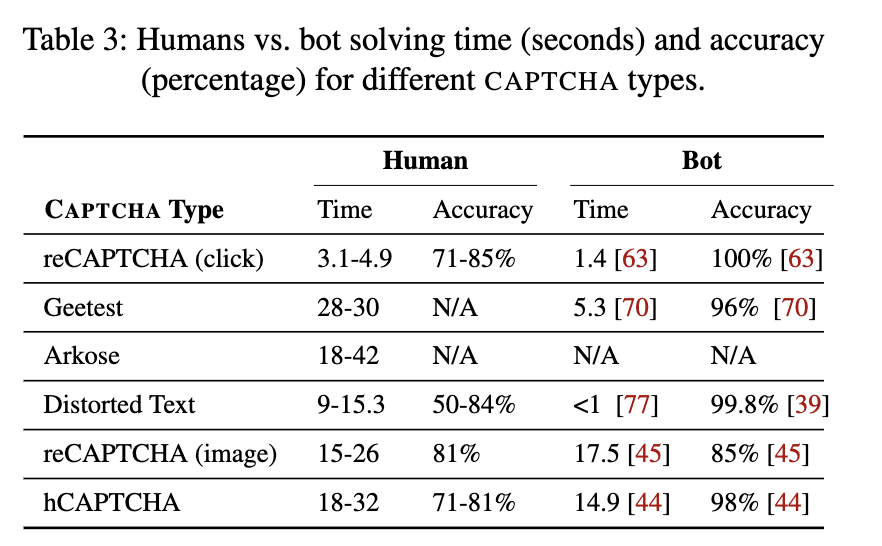
2023’s An Empirical Study & Evaluation of Modern CAPTCHAs provided concrete evidence that Bots now can outperform humans across common forms of CAPTCHA.
The findings of How Secure is Your Website? A Comprehensive Investigation on CAPTCHA Providers and Solving Services complement the research, concluding “CAPTCHA providers are failing to stop automated solvers. All selected popular third-party CAPTCHAs except FunCaptcha can be solved by CapSolver with a high success rate at a low price.”
Together, recent research shows that traditional CAPTCHAs cannot sufficiently distinguish humans from bots, and initiatives like Private Access Tokens do not seem to have the broad adoption necessary to offer a replacement.
I expect we’ll continue to see bimodal efforts: increasing behavior analysis and device profiling, like is done by Cloudflare Turnstile and ReCAPTCHA, but also more adoption of privacy-preserving protocols. So far however, the latter have relied on centralized providers and often on expensive ecosystems. While vendors like Arkose Labs (behind FunCaptcha) show that we can continue to use hard AI problems as CAPTCHAs, the chasm of “easy for humans, hard for bots” seems to have mostly closed.
Additional References
- A brief history of CAPTCHA
- The origin of CAPTCHA and reCAPTCHA
- How does the “I’m not a robot” checkbox work?
- CAPTCHA: Using Hard AI Problems for Security
- How CAPTCHAs work | What does CAPTCHA mean?
- CAPTCHA: The story behind those squiggly computer letters
- Moving from reCAPTCHA to hCaptcha
- MIT - Luis von Ahn
- CAPTCHA and its Alternatives: A Review
- Inaccessibility of CAPTCHA
- recaptcha.net - About us
- Private Access Tokens, also not great
- Who Made That Captcha?
- Breaking Audio CAPTCHAs
- Deciphering Old Texts, One Woozy, Curvy Word at a Time
- Telling Humans and Computers Apart (Automatically)