
AWS S3 Intelligent Tiering (S3-IT) can almost always save you money, with minimal effort. However, that almost can be paralyzing.
This is especially acute the longer you wait to take adopt S3-IT. All migrations are hard. If you’re uncertain about the cost and performance implications, it’s easy to get stuck.
This post is a playbook. Evaluate S3-IT for your business with napkin math, and build the confidence to go save some money!
🔥 AWS states that S3-IT saves 40-68% on storage costs.
Those numbers are real: I’ve seen it save >50% on the overall bill.
Quick Background
S3 Storage Classes balance “performance, data access, resiliency, and cost requirements.”
Intelligent Tiering is a special Storage Class. When you place an object in S3-IT, AWS will automatically monitor the object’s access patterns. The object then gets moved to the most appropriate storage tier within S3-IT.
Objects start in the Standard Tier. After 30 days without access, they move to the Infrequent Access tier. After 90 days without access, they move to the Archive Instant Access tier. You can optionally enable an extra move to Deep Archive Access after 180 total days without access.
If you access an object in a non-standard tier, there is no extra retrieval charge but it will move back to S3 Standard storage.
The easy answers
There are a reasonable concerns that are simple to discount:
Performance S3-IT (without Deep Archive) offers the same performance as S3 Standard. You get “milliseconds latency and high throughput performance.”
Migration The migration to S3-IT is zero downtime, with no performance implications, using lifecycle policies.
The nuance
Consider some factors more carefully:
Availability: S3-IT availability is 99.9%, versus S3 Standard’s 99.99%. In practice, this means you’ll see an increase in object retrieval failures post-migration. But 99.99% means you’re still frequently encountering those failures at scale and should have already built in resiliency. This shouldn’t be a blocker for the average use case.
Overhead: S3-IT adds a few incremental costs (all prices assume us-east-1)
- S3 Lifecycle Transitions will cost $0.01 for every 1,000 objects moved from S3 Standard into S3-IT
- S3-IT incurs a monitoring charge of $0.0025 for every 1,000 objects stored. This is exclusive of objects <128kb - which are not monitored and are always stored in S3 Standard.
- For each object archived to the Archive Access tier or Deep Archive Access tier in S3 Intelligent-Tiering, Amazon S3 uses 8 KB of storage for the name of the object and other metadata (billed at S3 Standard storage rates) and 32 KB of storage for index and related metadata (billed at S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive storage rates)
- name & metadata: 125 000 **objects = 1GB overhead
- index and related metadata: 31 250 objects = 1GB overhead
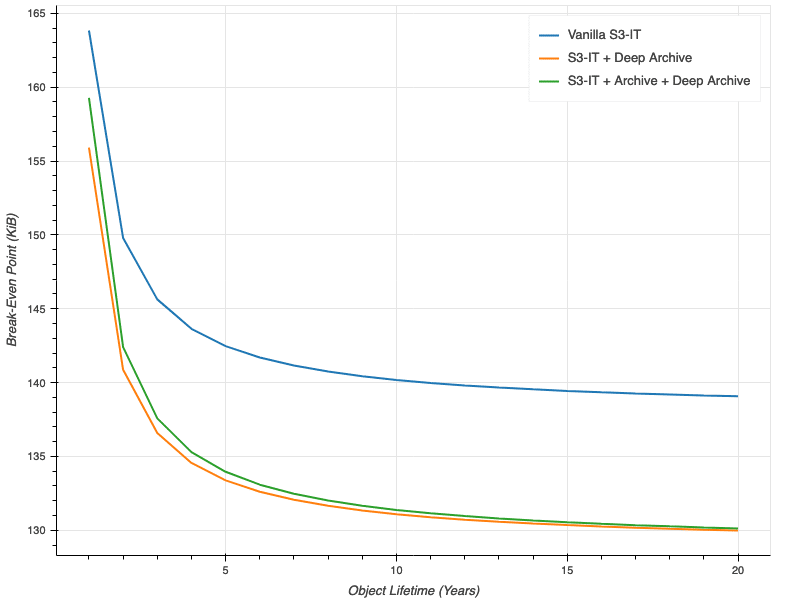
- The wonderful economists over at the Duckbill Group put together a chart on the break even point. Note that this only accounts for storage costs, and not the lifecycle transition (assuming you don’t place objects directly in S3-IT on creation!)
Lifecycle Policies are a one way door: This is a bit nerve-racking, but once you move object from S3 Standard to S3-IT, there is no moving the data back (via lifecycle policy). This most acutely impacts you by putting a ceiling on potential cost savings for existing objects. You’ll always have to pay the S3-IT overhead, even if you later devise a more sophisticated or home-brewed method of assigning objects to S3 Standard-IA. You can of course move the data back through non-lifecycle policy approaches, but that’s expensive and complex. Despite this, S3-IT is still worthwhile. The number of companies that will actually implement their own storage class automation with any level of sophistication is tiny, and the opportunity cost of assuming your company will hit that maturity and avoiding the immediate benefit of S3-IT is generally bigger than the long term benefit of waiting.
Opt-In Asynchronous Tiers: S3-IT optionally offers use of the exceptionally cost effective (95% cheaper than Standard!) Archive Access and Deep Archive Access tiers. However, these tiers introduce asynchronous retrieval patterns, where you need to restore objects before retrieving them. In practice, it introduces significant complexity for usage of the bucket when objects can sometimes require asynchronous retrieval. I wouldn’t recommend opting in for most usage.
Tips for making the decision
Be data driven, but don’t get bogged down. S3-IT is almost always the right decision, however if you need to build confidence I recommend pulling the following data:
Total number of objects: while $0.01 for every 1,000 objects can sound cheap - it adds up, so it’s good to understand the cost you’ll pay when you turn on S3-IT. For example, Canva had 300 billion objects, which would cost $3 million to move!
Average object size, ideally by prefix (not just bucket): You can compute this at the bucket level using the default metrics for total size and total object count. One option is to enable the S3 Storage Lens advanced tier. If you go this route, don’t forget to shut down storage lens after, as $0.12-0.20 per million objects monitored per month can add up! You can also use an S3 Inventory Report, which will be cheaper (0.0025 per million objects listed) but require more effort.
Access patterns, via Storage Class Analysis: Eyeball to confirm that objects are not all frequently accessed, in which case S3-IT will have minimal space for impact and may result in an overall cost increase due to the monitoring fees.
Derisking S3-IT Migration
There are a few cases where an S3-IT migration can be counterproductive:
- When you are storing data that is known to be very infrequently accessed, you should save on the monitoring and movement costs and store it directly in low-access storage tiers like Glacier Instant Retrieval
- When you are storing data that is of small volume spread across a large number of objects, the payback period can be on the order of years at high upfront cost.
It should be straightforward to discount the first case based on your usage patterns, or you can dive into the data as discussed above. One tactic to unblock an S3-IT migration is to take a simple step to protect against the downside of the second case: start your S3-IT migration by only applying the Lifecycle Policy to “large” objects. I’ve found 500kb is a good concrete number to use.
S3-IT Alternatives
We can quickly look at some alternatives to S3-IT. Despite mentioning them, they’re all generally more complicated to validate the cost implications, and often more complicated to put in place. I wouldn’t recommend them unequivocally!
Directly store data in cold storage: For S3 usage that does not need any frequent access, you’ll have slightly better cost if you just directly store the data in the appropriate storage tier. This saves the S3-IT monitoring and lifecycle policy transition costs.
Programmatically tier storage on the client side: especially if you ship a unified S3 client, you could support client-side storage in the appropriate tier based on a variety of factors - like the feature, objects size, etc - at time of creation.
Programmatically tier storage on the “server” side: you could build your own version of S3-IT. A naive version might have specific bucket- and prefix-based rules. A more sophisticated version might continuously assess object access patterns and then move object. But why would you do this undifferentiated heavy lifting?
Conclusion
Overall, if you’re reading this blog post and have the ability to go get your company on S3-IT:
- It’s probably the right fit for your company (i.e you don’t have an entire team working on this problem already)
- You should do that!