
12/13/23: This post has been updated with details on leveraging Date Partitioning.
11/20/23: AWS has lauched Data Partitioning for S3 Access Logs. I strongly recommend enabling this for your buckets. Going forward, it should enable Athena (and other) queries without post processing.
Here’s what you should do about S3 Logging
- Turn on S3 Access Logs with event time Date Partioning for any non-public bucket. Save them for a rainy day, at which point you can query them with Athena, somewhat painfully at scale
- Use Cloudtrail Data Events with Event Selectors, on buckets of reasonable volume where you require detective controls on reads or writes
- If you have a high volume bucket that needs detective controls, you’ll want to deploy a Lambda to process S3 Access Logs as they’re delivered
About S3 Logging
S3, the first generally available AWS service, is over 15 years old. It stores over 100 trillion objects.
While S3 is well documented, good answers on logging are buried in the noise. Google, and you’ll find 100 blog posts, a half dozen AWS-published documents, and few clear answers.
Starting with the basics, there are three types of logs available for S3:
- Management events: if you have CloudTrail set up, you will have logs within your trail of control plane operations by default. This does not include object-level S3 API activity.
- Data events (released 2016): Cloudtrail can also be configured to log object-level operations using Data Events. Event Selectors allow you to specify
ReadOnlyorWriteOnlyevents to log, and Advanced Event Selectors includeeventSource,eventNameandeventCategory. - Server Access Logs: Request logging is also available for S3. It can only be configured with another S3 bucket as the target for log delivery.
Pro Tip: if you want to get tricky, you can set up SSE-KMS with a customer-managed key for S3. This provides an alternative for data plane events via the logging on decryption h/t Aidan Steele
An unnecessary defense of logging
This post is not intended to convince you that logging is important. In short, logging is an obvious practice, recommended by AWS for S3 specifically, and required to various extents by every compliance scheme and regulatory standard (ex. NIST SP 800-53 Rev. 5)
However, it is worth assessing what your goals are for the logs you’re collecting. Are you gathering them to detect attackers? To support forensics? To enable threat hunting? Or just to check a compliance box?
Comparing S3 Logs
No matter your goals, you should set up Cloudtrail. You should do it using an Organization Trail. You should log management events. Few controls in AWS are as universally applicable.
It gets more complicated when you start looking at Cloudtrail Data Events and Server Access Logs. AWS’ “Logging options for Amazon S3” offers the best holistic comparison.
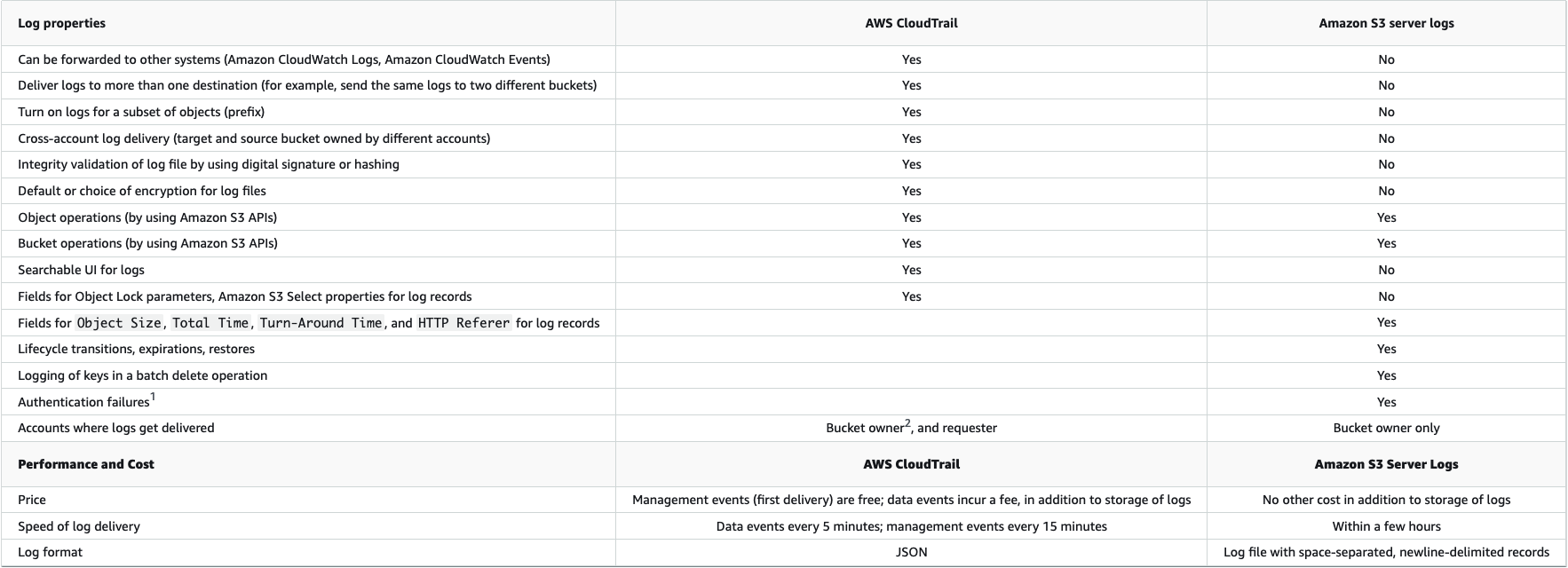
Data Events vs. Server Access Logs
| Data Events | S3 Server Access Logs |
|---|---|
| Support granular Event Selectors | Offer detail that is not available in Data Events, like HTTP Referer |
| N/A | Log the Object Size and HTTP Referer |
| Configured via Cloudtrail, and can easily be managed centrally | Have to be configured on each bucket |
| Logs can be routed to various and multiple systems | Can only log to another S3 bucket in the same region and account |
| Reliable and ~fast delivery (under 5 minutes, often much sooner) | Delivery is best effort and is “within a few hours” |
| Generally, are well supported as a data source in your SIEM of choice | Require a Lambda for detective controls, [1] date partioning can enable querying (once enabled, post 2023) |
| Cost per Data Event, for storage (both in AWS and your SIEM), and for SIEM ingestion (often) | Cost for storage in S3 |
[1] See Working with Server Access Logs
Mixed messages
Part of the confusion stems for a lack of a clear best-of-breed solution from AWS. By default, your account will have neither Data Events or S3 Server Access Logs. There is plenty of bad guidance floating around that, in summary, says “turn it all on.” That approach disregards and disrespects the real world implications of cost, complexity, and work to operationalize these tools.
Even AWS resources give mixed recommendations:
- The “Amazon S3 Monitoring and auditing best practices” say to both “Enable Amazon S3 server access logging” and to enable Cloudtrail Data Events
- But the “Logging Amazon S3 API calls using AWS CloudTrail” guide offers helpful warnings against generically enabling Data Events
- Compliance schemes only mention “S3 bucket server access logging should be enabled”
- The “CIS AWS Foundations Benchmark” only recommends bucket access logging on the Cloudtrail bucket itself
- The “AWS Foundational Security Best Practices (FSBP) standard” recommends bucket access logging for all buckets
- Trusted Advisor gives a “Yellow” alert if S3 Bucket Logging is not enabled
- The “Security Baseline Workshop” recommends “CloudTrail Data Events for any S3 buckets that store sensitive or business critical data”
- The “AWS CloudTrail Best Practices” blog post says “AWS recommends that you … check that at least one trail is logging S3 data events for all S3 buckets”
… and yes, so does ChatGPT
In practice
Up top, we presented the guidelines for S3 logging. Applied, this might look like the following:
-
In order to proactively enforce any control in the cloud, you should be codifying your infrastructure as code (i.e. Terraform). This is key to mediate and audit changes. In such an environment, you should implement standard modules for key services like S3. These modules offer an opportunity to set sane defaults and shared configuration.
For S3, you can configure your module to enable S3 Access Logs by default. Take care, as you’ll need to handle each account:region pair where you will be hosting S3 buckets. -
With your buckets represented as code, you can use a SAST tool or linter to:
a. detect use of the raws3_bucketmodule instead of your hardened module
b. prompt developers with guidance on when and how to configure Cloudtrail data events
c. detect when Cloudtrail data events are enabled on a new bucket -
When you detect added buckets with Cloudtrail data events, take the opportunity to write the appropriate detections for unapproved or unexpected access.
-
If you need detective controls on top of S3 Access Logs, you should set up a Lambda trigger for the bucket. The Lambda will need to parse the log file and implement detection logic over the logs. Reach out in CloudSecForum if you need sample code!
-
To buffer your code-based detections, you can also rely on your Cloud Security Posture Management (or equivalent buzzword) tool to enforce an invariant on your desired logging.
Don’t forget to watch out for:
- Cloudtrail Data Events get expensive fast - the mix of charges for the data events themselves, plus storage across both cloudtrail and your SIEM, and then SIEM ingestion and processing.
- It can never be mentioned enough, but it’s easy to get bit by cyclic logging, especially if you move to a log-by-default posture.
- S3 Server Access Logs are easy to stow for a rainy day, make sure to enable date partioniong or they’ll be hard to use in a pinch
Working with Server Access Logs
By default, Server Access Logs are placed directly in the configured prefix. Logs have the following object key format TargetPrefixYYYY-mm-DD-HH-MM-SS-UniqueString/. This means that AWS Athena (and similar tools) cannot partition the data, and have to scan the entire set. AWS documentation elides this complexity.
Date Partioning: Data Partitioning for S3 Access Logs was launched at re:Invent 2023. I recommend enabling it in all cases, generally with event time prefixes, to support accurate retroactive searching by activity time.
For logs stored without Date Partitioning: AWS has documented an ELT pattern built on Glue. As an alternative, I recommend using a Lambda trigger to automate moving log files under a daily (or more granular) prefix. This will allow more trivial analysis with Athena. You could also explore rolling up the log files.
You could also directly post-process these logs, looking at an example parser like the one from Dassana.
S3 Logging
When planning your logging, consider the following characteristics of each bucket:
- Volume of writes expected
- Volume of reads expected
- Risk of unauthorized writes
- Risk of unauthorized reads
- Frequency of human/user access
Then, based on those parameters, go:
- Turn on S3 Access Logs for any non-public bucket. Save them for a rainy day, at which point you can query them with Athena, somewhat painfully at scale
- Use Cloudtrail Data Events with Event Selectors, on buckets of reasonable volume where you require detective controls on reads or writes
- If you have a high volume bucket that needs detective controls, you’ll want to deploy a Lambda to process S3 Access Logs as they’re delivered
- To actually allow querying of S3 Access Logs, invest in post processing
Additional References
- AWS S3 Logjam: Server Access Logging vs. Object-Level Logging
- Panther Labs: AWS Security Logging Fundamentals — S3 Bucket Access Logging, CloudTrail vs AWS Access Logs – Traffic Monitoring Options for S3
- Partition Athena by S3 object key prefix that is not a “folder”
Thank you to:
- Erik Steringer for prompting the inciting discussing in CloudSecForum, and all those who participated in the thread
- Aidan Steele for the feedback!